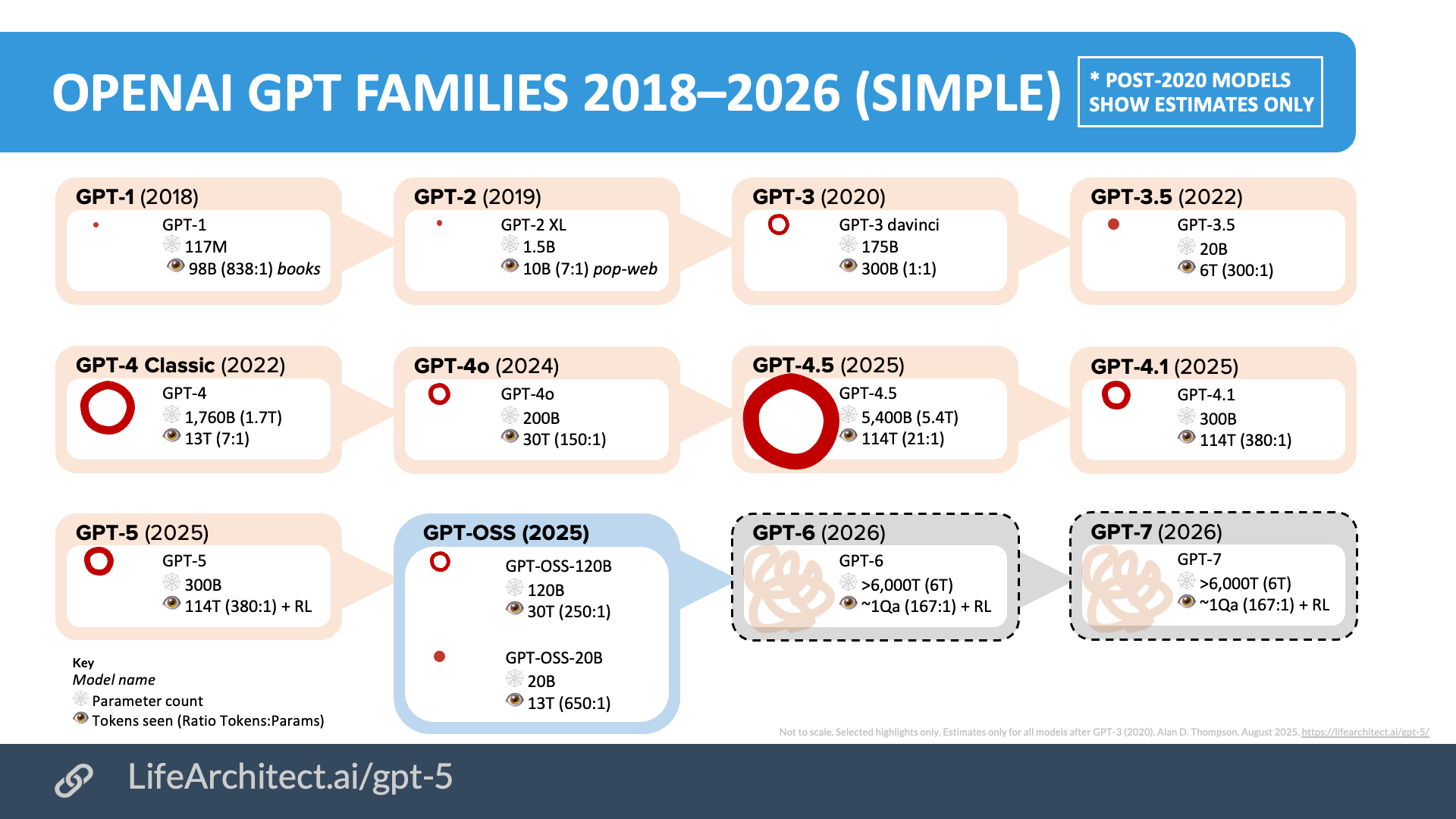
1. Экспоненциальный рост производительности frontier AI-моделей (логарифмическая шкала, семьи GPT от OpenAI 2018–2026 — отличная иллюстрация scaling в новой форме)
2. Главные bottleneck развития AI в 2026 году (пример роста энергопотребления дата-центров под AI — energy и compute как основные стены, как обсуждали в подкасте)

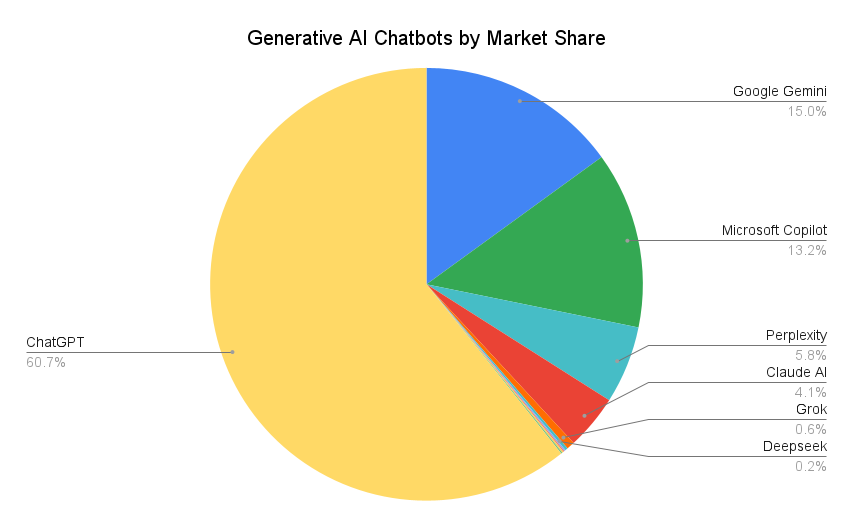
3. Распределение влияния ведущих LLM в 2026 году (реальная доля трафика/рынка generative chatbots на февраль 2026 — ChatGPT всё ещё доминирует, но гонка плотная)
4. Сдвиг фокуса: от pre-training к post-training и inference scaling (пирамида навыков AI-исследователей 2025–2026 — показывает, куда ушёл основной research effort: applied, frontier, post-training)

5. Распределение прогнозов по срокам достижения AGI (снимок 2026) (кумулятивные вероятности от разных источников — пик в 2027–2030, как и в подкасте, с urgency на ближайшие годы)
